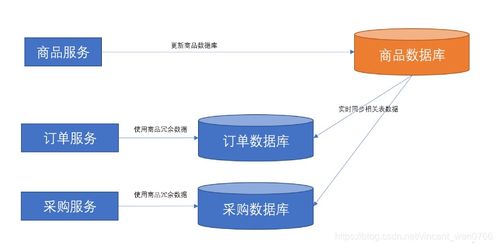
在微服务架构中,数据处理服务往往成为系统的核心枢纽,它不仅要处理自身业务逻辑,还要应对来自其他微服务的数据依赖需求。这种跨服务的数据依赖,如果处理不当,极易导致系统耦合度高、性能瓶颈、数据一致性问题,甚至引发服务雪崩。因此,设计一个能妥善解决数据依赖问题的数据处理服务,是微服务落地实践中的关键挑战。本文将系统探讨解决这一问题的核心策略与架构模式。
一、 问题根源:微服务数据依赖的典型挑战
微服务强调独立部署与自治,每个服务拥有自己的私有数据库。当服务A需要服务B的数据来完成业务时,就产生了数据依赖。在数据处理服务场景下,这种依赖尤为突出:
- 同步耦合与性能风险:直接通过同步API(如REST、gRPC)调用获取数据,会导致服务间强耦合,且链式调用易引发延迟放大和单点故障。
- 数据一致性难题:分布式环境下,如何保证数据处理服务使用的“外部数据”与其源头的实时一致性?采用最终一致性时,业务逻辑如何处理中间状态?
- 查询效率低下:为满足复杂查询(如跨多服务数据的联合查询),若频繁进行服务间调用,效率极低,且给被依赖方带来巨大压力。
- 事务管理复杂:跨服务的数据更新难以实现传统的ACID事务,需要引入Saga等复杂模式,增加了开发和运维的复杂性。
二、 核心解决策略:从耦合调用到数据协同
解决之道在于将紧耦合的“数据索取”转变为松耦合的“数据协同”。以下是几种经过验证的核心架构策略:
1. API组合模式
这是最直接的方式,由数据处理服务作为协调者,通过调用其他服务的API,在内存中组合所需数据。适用于依赖服务少、性能要求不高的场景。为优化性能,可并行调用多个依赖API,并使用断路器(如Hystrix、Resilience4j)防止级联故障。
2. 命令查询职责分离与数据副本
这是应对复杂查询和强依赖的利器。其核心思想是:
- CQRS:将数据处理服务的“命令”(写操作,更新自身数据)与“查询”(读操作,可能需要外部数据)分离。
- 数据副本:在数据处理服务的私有数据库中,维护一份所依赖外部数据的只读副本。这份副本通过异步机制(如下文的“事件驱动”)从源服务同步而来。
优势:查询完全本地化,性能极高;将运行时依赖转变为设计/部署时依赖,提升了系统的可用性与韧性。
3. 事件驱动架构
这是实现数据副本同步、达成最终一致性的黄金标准。
- 机制:当被依赖的服务(数据源)其数据发生变更时,并不直接通知数据处理服务,而是向一个消息中间件(如Kafka、RabbitMQ)发布一个“领域事件”。数据处理服务作为订阅者,监听这些事件,并据此异步地更新自己数据库中的副本。
- 优势:彻底解耦,服务间仅通过事件契约通信;天然支持最终一致性;系统扩展性强,新服务可以轻松订阅所需事件而不影响现有服务。
三、 数据处理服务的稳健架构设计
综合运用以上策略,一个健壮的数据处理服务可以采用如下分层架构:
- 接入层:提供REST/gRPC API,接受外部请求。
- 命令处理层:处理写入请求,更新自身核心数据,并可能发布事件(如“数据处理完成事件”)。
- 事件处理层:订阅外部事件,更新本地数据副本。这是解决依赖问题的关键模块。
- 本地数据存储层:包含两部分:
- 核心数据:服务自身产生和管理的权威数据。
- 副本数据:从其他服务同步而来的、用于查询和业务逻辑的数据。需明确标识其“非权威”来源。
- 查询层:基于CQRS,提供专用的查询模型和接口。所有查询仅操作本地数据库(核心数据+副本数据),实现高效响应。
四、 实践建议与注意事项
- 权衡与选择:不是所有依赖都需要数据副本。对于实时性要求极高或数据量巨大的依赖,可仍采用API组合,但需做好熔断和降级。采用“事件+副本”模式会增加架构复杂性和数据延迟,需根据业务容忍度决策。
- 事件设计:事件应携带足够的信息(通常是变更后的完整状态或关键字段),并设计成自描述的、不可变的。使用事件版本化来兼容演进。
- 副本数据治理:明确副本数据的生命周期和一致性等级(如延迟数秒)。建立监控,确保事件消费的及时性与正确性。考虑使用CDC工具监听数据库日志来生成事件。
- 容错与幂等:事件处理必须实现幂等性,以应对网络重试导致的消息重复。设计补偿机制,处理同步失败或数据不一致的异常情况。
###
微服务间的数据依赖问题,本质是分布式系统数据管理的挑战。对于数据处理服务而言,摒弃“实时获取、随用随取”的传统思维,转向“事件驱动、异步复制、本地查询”的架构范式,是构建高可用、高性能、松耦合系统的有效路径。通过精心设计的CQRS、事件溯源和数据副本机制,数据处理服务可以化身为一个既能高效自治,又能与整个微服务生态系统协同工作的稳健核心,从而真正释放微服务架构的潜力。